

The Chronicles of Deepseek Chatgpt
페이지 정보

본문
 A Mixture of Experts (MoE) is a solution to make AI fashions smarter and more efficient by dividing duties amongst multiple specialised "specialists." Instead of utilizing one huge mannequin to handle the whole lot, MoE trains a number of smaller models (the consultants), each focusing on specific types of data or duties. Also: Is DeepSeek's new image mannequin one other win for cheaper AI? Yann LeCun, chief AI scientist at Meta, stated that DeepSeek's success represented a victory for open-source AI fashions, not necessarily a win for China over the U.S. The numbers inform a exceptional story about Deepseek's efficiency. We had numerous jumps in coaching effectivity and other optimizations, but the leap from "prohibitively costly to even attempt" to "you can in all probability run this on your graphics card to deal with most of your problems" is huge. Without these chips, training massive AI fashions became troublesome. So kind of "stealing" OpenAI’s coaching information that OpernAI kinda stole from everyone else. Thanks to your form phrases Mike and for taking the time to depart a comment.
A Mixture of Experts (MoE) is a solution to make AI fashions smarter and more efficient by dividing duties amongst multiple specialised "specialists." Instead of utilizing one huge mannequin to handle the whole lot, MoE trains a number of smaller models (the consultants), each focusing on specific types of data or duties. Also: Is DeepSeek's new image mannequin one other win for cheaper AI? Yann LeCun, chief AI scientist at Meta, stated that DeepSeek's success represented a victory for open-source AI fashions, not necessarily a win for China over the U.S. The numbers inform a exceptional story about Deepseek's efficiency. We had numerous jumps in coaching effectivity and other optimizations, but the leap from "prohibitively costly to even attempt" to "you can in all probability run this on your graphics card to deal with most of your problems" is huge. Without these chips, training massive AI fashions became troublesome. So kind of "stealing" OpenAI’s coaching information that OpernAI kinda stole from everyone else. Thanks to your form phrases Mike and for taking the time to depart a comment.
While the first sequence is very straightforward, the second is unimaginable (they're simply three random phrases). This leads to quicker processing speeds while being price-effective. Kress said Bloomberg is building a 50 billion-parameter mannequin, BloombergGPT, to allow monetary natural language processing tasks corresponding to sentiment analysis, named entity recognition, news classification and query-answering. However, building an all-objective nice language model could be very exhausting and principally expensive. Their V3 mannequin is the closest it's important to what you most likely already know; it’s a big (671B parameters) language mannequin that serves as a foundation, and it has a couple of things going on - it’s cheap and it’s small. It’s that it's cheap, good (enough), small and public at the identical time while laying utterly open elements a few mannequin that were thought-about enterprise moats and hidden. This makes AI systems more environment friendly, reducing price and speed while retaining performance strong. While it’s funny, it reveals exactly (and transparently!) how the model is making an attempt to solve the complicated query in various different damaged down steps before it stops utterly. Each node also retains observe of whether or not it’s the top of a word.
I hyperlink some extremely really useful public sources at the tip of this article. This is all second-hand data but it does come from trusted sources in the React ecosystem. Let’s construct an AI strategy that’s as pragmatic as it's ambitious-as a result of your enterprise deserves greater than experiments. I believe that’s why lots of people concentrate to it," Heim mentioned. From "Here’s why this is a technological leap" to "the ‘transformer models’ may seem like magic, however here’s how they work’ to ‘who are the large gamers in the house,’ Marvin walked us by way of all of it. A minimum of, that has been the current reality, making the trade squarely in the agency hands of big players like OpenAI, Google, Microsoft. The opposite greater gamers are also doing this, with OpenAI having pioneered this approach, however they don’t tell you, as a part of their business mannequin, how they are doing it precisely. ChatGPT is useful in lots of areas, like enterprise and schooling. Having an all-objective LLM as a enterprise model (OpenAI, Claude, and so forth.) might need simply evaporated at that scale. Building "a" mannequin is not exhausting. It was a stark reminder: we are constructing a company for markets in the future, not just for right now.
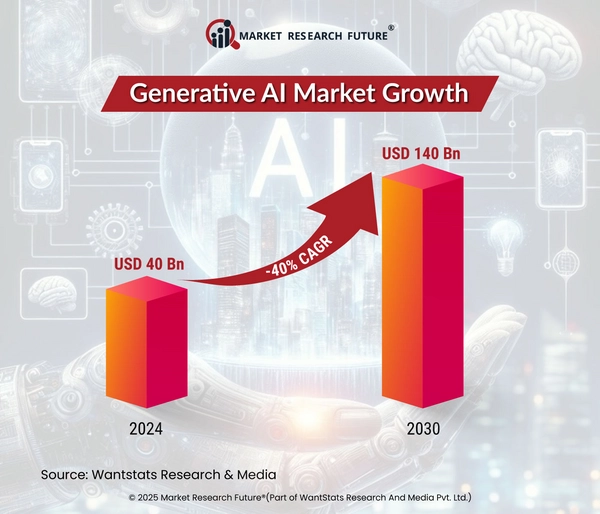 The money in markets is usually segmented into different elements. We were forward in AI, which was a huge advantage, but we were terrified that corporations like Microsoft or Google could just dunk on us by throwing more money at the problem. It's like a group of specialists as a substitute of a single generalist, resulting in extra exact and environment friendly resolution-making. The Guardian tried out the main chatbots, including DeepSeek, with the assistance of an skilled from the UK’s Alan Turing Institute. It’s like having an expert explain something in a way that a newbie can still understand and use effectively. Join now (it’s free)! Samosa, Social. "OpenAI launches free 15-minute phone calls with ChatGPT". This leads to a different humorous situation, which is now OpenAI saying that DeepSeek was "using our output to train their model". Both OpenAI and Anthropic already use this system as well to create smaller models out of their larger fashions. Users concerned about trying out DeepSeek can entry the R1 mannequin through the Chinese startup’s smartphone apps (Android, Apple), in addition to on the company’s desktop web site. A big model (the "teacher") generates predictions, and a smaller mannequin (the "student") learns to mimic these outputs.
The money in markets is usually segmented into different elements. We were forward in AI, which was a huge advantage, but we were terrified that corporations like Microsoft or Google could just dunk on us by throwing more money at the problem. It's like a group of specialists as a substitute of a single generalist, resulting in extra exact and environment friendly resolution-making. The Guardian tried out the main chatbots, including DeepSeek, with the assistance of an skilled from the UK’s Alan Turing Institute. It’s like having an expert explain something in a way that a newbie can still understand and use effectively. Join now (it’s free)! Samosa, Social. "OpenAI launches free 15-minute phone calls with ChatGPT". This leads to a different humorous situation, which is now OpenAI saying that DeepSeek was "using our output to train their model". Both OpenAI and Anthropic already use this system as well to create smaller models out of their larger fashions. Users concerned about trying out DeepSeek can entry the R1 mannequin through the Chinese startup’s smartphone apps (Android, Apple), in addition to on the company’s desktop web site. A big model (the "teacher") generates predictions, and a smaller mannequin (the "student") learns to mimic these outputs.
If you loved this post and you would certainly like to receive additional details concerning Deep Seek kindly see the website.
- 이전글No More Mistakes With Deepseek Ai 25.02.06
- 다음글The Deepseek Ai Trap 25.02.06
댓글목록
등록된 댓글이 없습니다.