

By no means Lose Your Deepseek Once more
페이지 정보

본문
To flee this dilemma, DeepSeek separates specialists into two types: shared experts and routed consultants. DeepSeek’s method essentially forces this matrix to be low rank: they choose a latent dimension and specific it because the product of two matrices, one with dimensions latent times mannequin and one other with dimensions (variety of heads · For instance, GPT-3 had 96 attention heads with 128 dimensions every and 96 blocks, so for each token we’d need a KV cache of 2.36M parameters, or 4.7 MB at a precision of 2 bytes per KV cache parameter. In the case of DeepSeek, certain biased responses are deliberately baked proper into the model: for instance, it refuses to interact in any discussion of Tiananmen Square or other, fashionable controversies associated to the Chinese authorities. The perfect keyword isn’t some mythical beast; it’s right there waiting to be uncovered. DeepSeek is sturdy on its own, however why cease there? Stop ready for the perfect second, take motion now, and transform your Seo strategy. Imagine yourself standing at a crossroad of Seo technique, and DeepSeek is that GPS that navigates you through pitfalls and straight into the traffic of your dreams.
 Mobile Integration: DeepSeek OCR API can be used on iOS and Android platforms, permitting builders to embed it into cell purposes and supply cross-platform OCR functionality. Anyone managed to get DeepSeek API working? Use Postman to check API connectivity4. Use the 7B if they will carry out well for your process. This naive price may be introduced down e.g. by speculative sampling, nevertheless it offers a good ballpark estimate. This cuts down the dimensions of the KV cache by a factor equal to the group size we’ve chosen. In models such as Llama 3.Three 70B and Mistral Large 2, grouped-question consideration reduces the KV cache size by round an order of magnitude. The most well-liked manner in open-supply fashions to date has been grouped-query attention. The basic downside with methods akin to grouped-question consideration or KV cache quantization is that they involve compromising on mannequin high quality in order to cut back the size of the KV cache. Because the one way previous tokens have an affect on future tokens is through their key and value vectors in the attention mechanism, it suffices to cache these vectors.
Mobile Integration: DeepSeek OCR API can be used on iOS and Android platforms, permitting builders to embed it into cell purposes and supply cross-platform OCR functionality. Anyone managed to get DeepSeek API working? Use Postman to check API connectivity4. Use the 7B if they will carry out well for your process. This naive price may be introduced down e.g. by speculative sampling, nevertheless it offers a good ballpark estimate. This cuts down the dimensions of the KV cache by a factor equal to the group size we’ve chosen. In models such as Llama 3.Three 70B and Mistral Large 2, grouped-question consideration reduces the KV cache size by round an order of magnitude. The most well-liked manner in open-supply fashions to date has been grouped-query attention. The basic downside with methods akin to grouped-question consideration or KV cache quantization is that they involve compromising on mannequin high quality in order to cut back the size of the KV cache. Because the one way previous tokens have an affect on future tokens is through their key and value vectors in the attention mechanism, it suffices to cache these vectors.
Multi-head latent attention (abbreviated as MLA) is an important architectural innovation in DeepSeek’s models for lengthy-context inference. We’re speaking specialized AI fashions specifically skilled to excel in certain areas like video creation, course of automation, voice generation, analysis, you identify it. This is the place the title key-value cache, or KV cache for short, comes from. To avoid this recomputation, it’s environment friendly to cache the related inside state of the Transformer for all previous tokens and then retrieve the outcomes from this cache when we'd like them for future tokens. While it’s certainly higher at providing you with a glimpse into the behind-the-scenes process, it’s still you - the user - who needs to do the heavy-lifting of fact-checking and verifying that the advice it offers you is indeed right. The full technical report comprises loads of non-architectural details as effectively, and i strongly advocate studying it if you wish to get a greater concept of the engineering problems that have to be solved when orchestrating a moderate-sized coaching run. DeepSeek online has not too long ago launched DeepSeek v3, which is at the moment state-of-the-artwork in benchmark efficiency among open-weight models, alongside a technical report describing in some detail the coaching of the model.
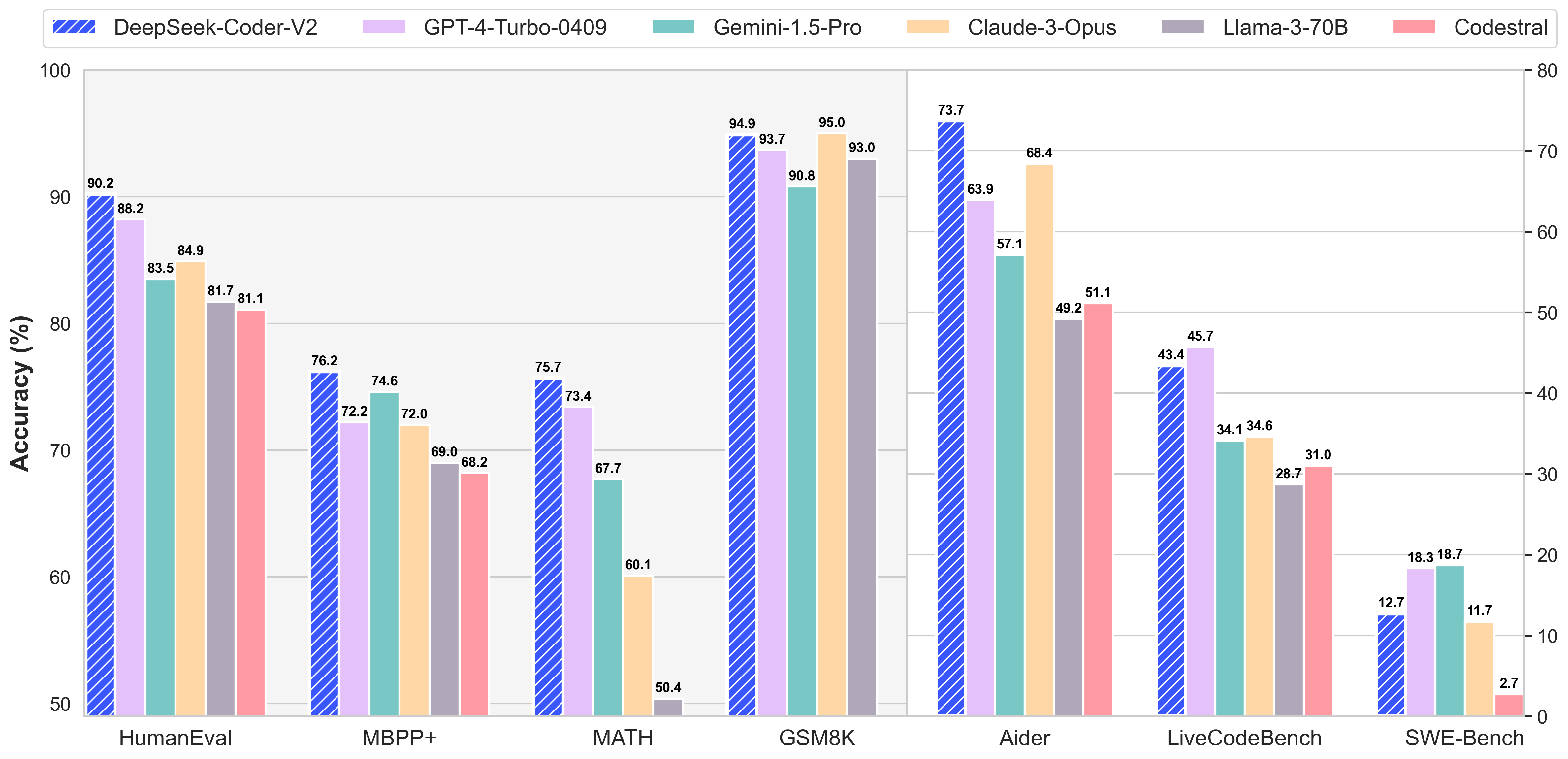
From the DeepSeek v3 technical report. The DeepSeek LLM family consists of 4 fashions: DeepSeek LLM 7B Base, DeepSeek LLM 67B Base, DeepSeek LLM 7B Chat, and DeepSeek 67B Chat. What’s new: DeepSeek announced DeepSeek-R1, a model household that processes prompts by breaking them down into steps. Get immediate access to breaking information, the hottest critiques, nice deals and useful ideas. So you’re nailing the fundamentals, great! Just observe the prompts-yes, that little nagging factor known as registration-and voilà, you’re in. Whether you’re revamping present strategies or crafting new ones, DeepSeek positions you to optimize content that resonates with search engines like google and yahoo and readers alike. Content optimization isn’t nearly sprinkling key phrases like confetti at a parade. The company leverages a unique approach, specializing in resource optimization whereas sustaining the high performance of its models. The full measurement of DeepSeek-V3 fashions on Hugging Face is 685B, which incorporates 671B of the main Model weights and 14B of the Multi-Token Prediction (MTP) Module weights. Multi-token prediction shouldn't be shown. Remember, in the sport of Seo, being a lone wolf doesn’t win as many battles as being the chief of a useful resource-rich pack. DeepSeek isn’t just a few run-of-the-mill instrument; it’s a recreation-changer that may redefine the way you tackle Seo, slicing through the digital noise like a seasoned maestro.
- 이전글 25.02.18
- 다음글비아그라 후기【텔레:@help4989】여성흥분제 효능 25.02.18
댓글목록
등록된 댓글이 없습니다.