

How To Show Deepseek Better Than Anyone Else
페이지 정보

본문
 Then DeepSeek shook the excessive-tech world with an Open AI-competitive R1 AI mannequin. I don’t assume in quite a lot of firms, you've gotten the CEO of - most likely crucial AI company in the world - name you on a Saturday, as a person contributor saying, "Oh, I actually appreciated your work and it’s unhappy to see you go." That doesn’t occur often. Tristan Harris says we're not ready for a world where 10 years of scientific research might be completed in a month. What it means is that there aren't any wonders. Then there may be something that one wouldn't expect from a Chinese firm: talent acquisition from mainland China, with no poaching from Taiwan or the U.S. The growth of Chinese-managed digital services has change into a significant topic of concern for U.S. A major differentiator for DeepSeek is its potential to run its own information centers, not like most different AI startups that depend on external cloud providers.
Then DeepSeek shook the excessive-tech world with an Open AI-competitive R1 AI mannequin. I don’t assume in quite a lot of firms, you've gotten the CEO of - most likely crucial AI company in the world - name you on a Saturday, as a person contributor saying, "Oh, I actually appreciated your work and it’s unhappy to see you go." That doesn’t occur often. Tristan Harris says we're not ready for a world where 10 years of scientific research might be completed in a month. What it means is that there aren't any wonders. Then there may be something that one wouldn't expect from a Chinese firm: talent acquisition from mainland China, with no poaching from Taiwan or the U.S. The growth of Chinese-managed digital services has change into a significant topic of concern for U.S. A major differentiator for DeepSeek is its potential to run its own information centers, not like most different AI startups that depend on external cloud providers.
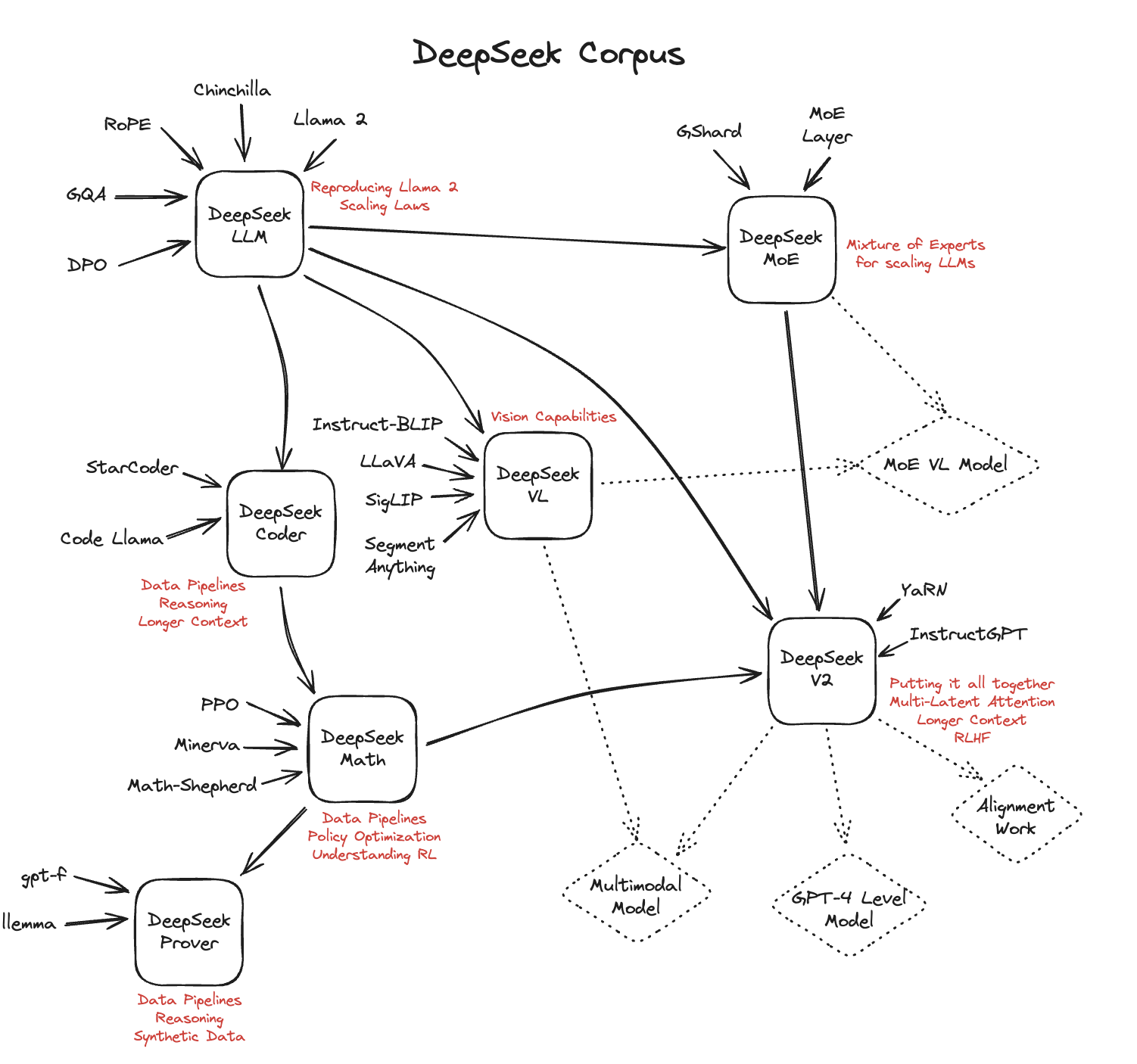 The lack of the ability of me to tinker with the hardware on Apple’s newer laptops annoys me a bit of, but I perceive that Apple soldered the parts to the board enable macbooks to be a lot more built-in and compact. These benchmarks highlight Deepseek Online chat-R1’s means to handle various duties with precision and efficiency. The results reveal that the Dgrad operation which computes the activation gradients and back-propagates to shallow layers in a series-like method, is highly sensitive to precision. This partnership ensures that developers are absolutely equipped to leverage the Deepseek free-V3 mannequin on AMD Instinct™ GPUs right from Day-zero offering a broader selection of GPUs hardware and an open software program stack ROCm™ for optimized efficiency and scalability. Meaning DeepSeek r1 was supposedly ready to achieve its low-cost mannequin on comparatively beneath-powered AI chips. While DeepSeek was trained on NVIDIA H800 chips, the app may be working inference on new Chinese Ascend 910C chips made by Huawei. And once they put money into running their own hardware, they are more likely to be reluctant to waste that investment by going again to a third-get together entry seller. I do think the reactions really present that individuals are frightened it's a bubble whether or not it turns out to be one or not.
The lack of the ability of me to tinker with the hardware on Apple’s newer laptops annoys me a bit of, but I perceive that Apple soldered the parts to the board enable macbooks to be a lot more built-in and compact. These benchmarks highlight Deepseek Online chat-R1’s means to handle various duties with precision and efficiency. The results reveal that the Dgrad operation which computes the activation gradients and back-propagates to shallow layers in a series-like method, is highly sensitive to precision. This partnership ensures that developers are absolutely equipped to leverage the Deepseek free-V3 mannequin on AMD Instinct™ GPUs right from Day-zero offering a broader selection of GPUs hardware and an open software program stack ROCm™ for optimized efficiency and scalability. Meaning DeepSeek r1 was supposedly ready to achieve its low-cost mannequin on comparatively beneath-powered AI chips. While DeepSeek was trained on NVIDIA H800 chips, the app may be working inference on new Chinese Ascend 910C chips made by Huawei. And once they put money into running their own hardware, they are more likely to be reluctant to waste that investment by going again to a third-get together entry seller. I do think the reactions really present that individuals are frightened it's a bubble whether or not it turns out to be one or not.
The truth that the hardware necessities to really run the mannequin are so much decrease than current Western fashions was at all times the facet that was most impressive from my perspective, and sure a very powerful one for China as effectively, given the restrictions on acquiring GPUs they should work with. Then, for each update, we generate program synthesis examples whose code options are prone to use the update. This course of is already in progress; we’ll update everybody with Solidity language effective-tuned fashions as quickly as they're finished cooking. The complete evaluation setup and reasoning behind the tasks are much like the previous dive. In line with the company, on two AI evaluation benchmarks, GenEval and DPG-Bench, the biggest Janus-Pro model, Janus-Pro-7B, beats DALL-E 3 in addition to models akin to PixArt-alpha, Emu3-Gen, and Stability AI‘s Stable Diffusion XL. We show its versatility by making use of it to a few distinct subfields of machine studying: diffusion modeling, transformer-based mostly language modeling, and learning dynamics. The prices to prepare fashions will continue to fall with open weight models, especially when accompanied by detailed technical experiences, but the pace of diffusion is bottlenecked by the necessity for difficult reverse engineering / reproduction efforts.
I assume it most is dependent upon whether or not they'll demonstrate that they'll continue to churn out more superior models in tempo with Western firms, especially with the difficulties in buying newer generation hardware to construct them with; their present model is definitely impressive, nevertheless it feels extra prefer it was supposed it as a method to plant their flag and make themselves known, a demonstration of what may be expected of them sooner or later, somewhat than a core product. Deepseek can understand and reply to human language just like a person would. As a result of talent inflow, DeepSeek has pioneered improvements like Multi-Head Latent Attention (MLA), which required months of improvement and substantial GPU utilization, SemiAnalysis reviews. Either approach, ever-growing GPU power will continue be vital to truly build/prepare fashions, so Nvidia should keep rolling with out too much situation (and perhaps finally start seeing a proper jump in valuation again), and hopefully the market will once again recognize AMD's importance as effectively. However, this figure refers solely to a portion of the overall training value- particularly, the GPU time required for pre-training.
- 이전글The Advantages Of Maximize Profits With Wholesale Disposable Vapes 25.02.18
- 다음글여성흥분제 구입방법【ddm6.com】여성흥분제 파는곳 25.02.18
댓글목록
등록된 댓글이 없습니다.